Case Studies
Case Study 1
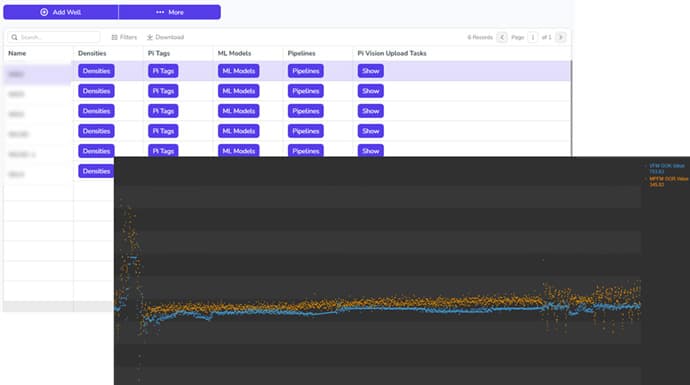
Introduction: Real-time sensors at the wellhead integrate data from metering sources like MPFM, wellhead sampling, and Control separator tests. This results in a substantial volume of data that needs cleaning using filters to handle missing data, outliers, and sampling-resampling issues. The project's objective was to develop a tool for Surveillance Engineers that enables real-time monitoring and historical analysis of well performance using data from different sources. Traditional surveillance tools operate on basic thresholds. These tools might not identify certain well behaviors such as condensate segregation drainage or the combined effects of scale deposition and well depletion. Our approach aims to address these challenges.
Results: An extensive exploratory analysis was undertaken on all the available raw data. In the process, a multitude of machine learning ML and deep learning DL methods and algorithms, both supervised and unsupervised, were rigorously tested. To enhance the accuracy and stability of the models, feature engineering techniques were employed. Additionally, the client's technical personnel underwent training in machine learning and deep learning concepts, ensuring the retention of this knowledge within the organization. Subsequently, the models were connected to PI servers using a Web API. As a result, the client now possesses the capability to build, train, and deploy models in a real-time environment.
Case Study 2
Optimizing Production Gathering Systems: An Integrated Network Model Proxy Using Neural Networks
Introduction: The INM proxy focuses on modeling and optimizing the Production Gathering system with Neural Network NN algorithms, targeting swift and precise hydraulic calculations. The prevailing Integrated Model leans on hydraulics physics and has achieved its quickest calculation capacity. The proposed approach employs NN to represent the physics model, aiming for calculations that are orders of magnitude faster. This acceleration enables the exploration of numerous optimization scenarios and effectively addresses the well routing optimization issue, which currently relies on manual estimations susceptible to error. This routing optimization could lead to an approximate 100 t/d incremental production. Furthermore, it equips Engineers with the tools to automatically select the most efficient routing in response to ongoing field condition changes.
Results: The case began with the preparation of raw data sourced from sensors alongside simulated datasets. An exhaustive exploratory analysis was conducted on all data sets, both raw and simulated. In our process, a range of machine learning ML and deep learning DL methods and algorithms were tested, spanning both supervised and unsupervised types. Emphasis was placed on feature engineering to heighten the accuracy and stability of the models. To ensure knowledge continuity, the client's technical staff was acquainted with machine learning and deep learning concepts. The outcome saw the client adopting ML models as proxies for their physics-based surface network models. Notably, the simulation duration plummeted dramatically, transitioning from 10 hours to just 2 minutes. This efficiency means the client can now execute significantly more simulation cases within brief time intervals.
Case Study 3
Implementation of Data lake
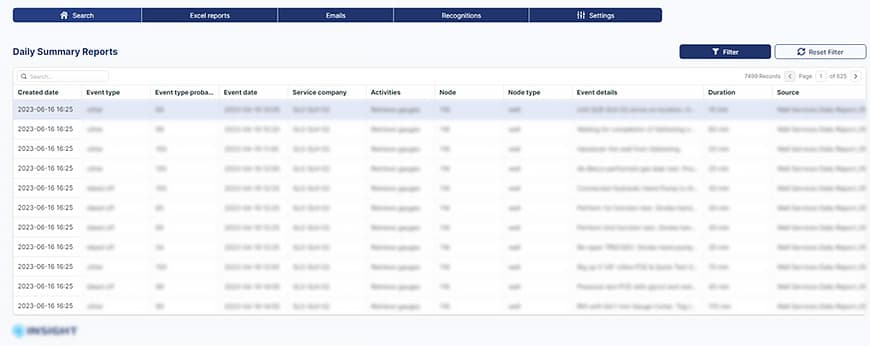
Introduction: The study outlines the implementation of a Datalake to facilitate the search of unstructured data sourced from diverse field and office reports. These reports cover various aspects of well performance, including tests and specific events such as shut in, opening, choking back, and hydrate/wax deposition. By integrating analytics of these well events with existing production dashboards, engineers can efficiently locate crucial events and descriptions that influence well production.
Results: The implemented data lake is now integrated with a variety of production report repositories and is also connected to emails. All previously unstructured data are being structured and saved into a structured database. Machine learning models have been trained to pinpoint events of importance to operators. Furthermore, all this information is now accessible from a singular access point. Data lake technology was introduced, specifically tailored for smart searching of well-related data and events.
Case Study 4
Derek Suite as integrated measurement management system
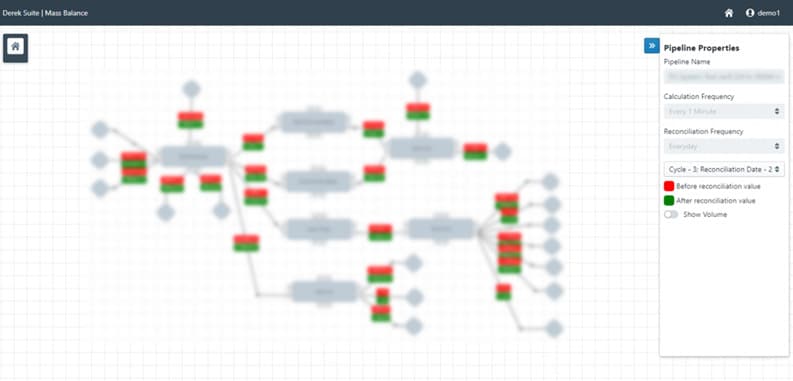
Introduction: The system consolidates production measurement validation, executes "near real time" calculations, manages changes related to allocation measurement and calculations, and performs data reconciliation and gross error detection. The system aims for auditability and traceability of measurements, pinpointing mismeasurements via data reconciliation, and computing total uncertainty. It permits the re-validation of raw data and highlights suspect meters or analyzers with errors or instruments showing drift.
Results: The complete production data management system was delivered to the client. With an intuitive interface and powerful tools which leverage AI and low-code development, the system helps the client to ensure the accuracy and integrity of their production data, increasing efficiency and reducing the risk of errors. The platform includes modules for traceability and auditability, enabling the client to easily track and verify their data for compliance purposes. For example, the platform can automatically check for inconsistencies in production data, alerting users to any potential issues before they become a problem. It can also track changes to data over time, providing an audit trail for compliance purposes. The platform's strong advantages are - browser based solution and integration capacity, i.e. it is not tied to certain technology. The platform is deployed without disrupting the existing architecture.
Case Study 5
Feasibility study - Data driven virtual flow metering for artificial lift wells
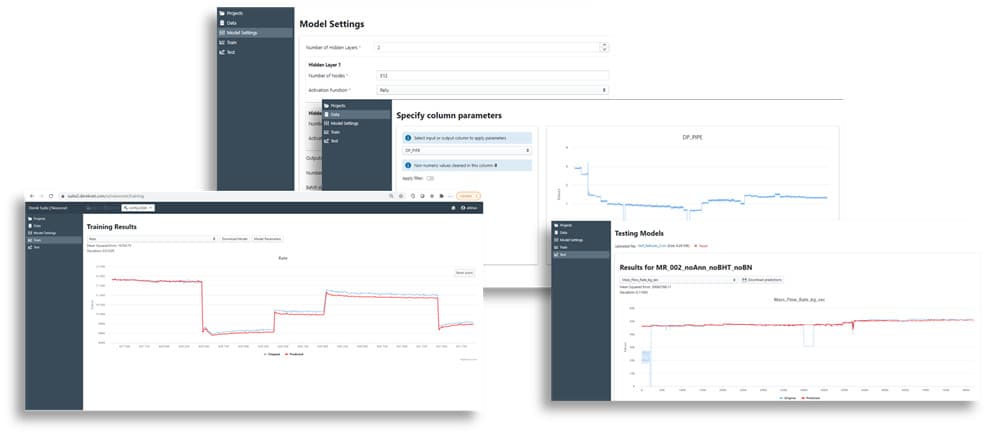
Introduction: It was required to perform a feasibility study for applicability of data driven methods as means of building virtual flow metering models for well parameters estimation. The wells are equipped with ESPs and surface/downhole sensors. The raw data stored in PI servers. Several wells share a single MPFM. The client already has an inhouse built physics based solution. However, the existing solution consumes lot's of engineer's time to tune the models in case one of the sensors is not available. Alternative solution is to implement a 100% data driven solution.
Results: First, our team of ML and Petroleum engineers conducted a raw data analysis to understand the quality of the data. The inconsistencies in the raw data were discussed with the client. Once the data preparation was done, several deep learning models were trained and tested. The deep learning models revealed that the MPFM readings started to behave differently. The study showed that the data driven models are applicable not only as VFMs but also to support detecting anomalies.